
Abstract
Physics simulators have shown great promise for conveniently learning reinforcement learning policies in safe, unconstrained environments. However, transferring the acquired knowledge to the real world can be challenging due to the reality gap. To this end, several methods have been recently proposed to automatically tune simulator parameters with posterior distributions given real data, for use with domain randomization at training time. These approaches have been shown to work for various robotic tasks under different settings and assumptions. Nevertheless, existing literature lacks a thorough comparison of existing adaptive domain randomization methods with respect to transfer performance and real-data efficiency. In this work, we present an open benchmark for both offline and online methods (SimOpt, BayRn, DROID, DROPO), to shed light on which are most suitable for each setting and task at hand. We found that online methods are limited by the quality of the currently learned policy for the next iteration, while offline methods may sometimes fail when replaying trajectories in simulation with open-loop commands.
Authored by Gabriele Tiboni, Karol Arndt, Giuseppe Averta, Ville Kyrki, Tatiana Tammasi.
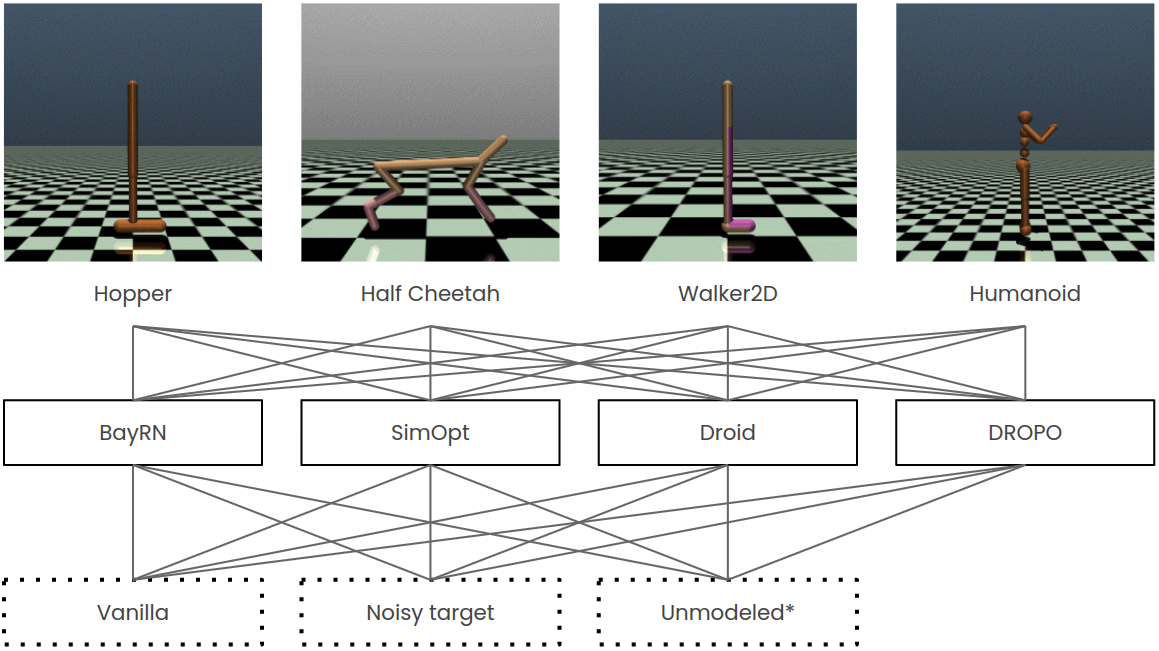 Overview of tasks, methods and dynamics settings used in this benchmark.
Overview of tasks, methods and dynamics settings used in this benchmark.*The source domain is under-modeled in the dynamics space.
Findings
Resetting the simulator state to each individual starting state when replaying offline trajectories—as in DROPO—seemed to solve the issue completely.
Citing
@InProceedings{tiboniadrbenchmark,
author="Tiboni, Gabriele and Arndt, Karol and Averta, Giuseppe and Kyrki, Ville and Tommasi, Tatiana",
editor="Borja, Pablo and Della Santina, Cosimo and Peternel, Luka and Torta, Elena",
title="Online vs. Offline Adaptive Domain Randomization Benchmark",
booktitle="Human-Friendly Robotics 2022",
year="2023",
publisher="Springer International Publishing",
address="Cham",
pages="158--173",
isbn="978-3-031-22731-8"
}